지난 MoCo에 이은 SimCLR 논문 리뷰! 논문의 제목은 A Simple Framework for Contrastive Learning of Visual Representations입니다. 논문에서 말하는 것처럼 네트워크는 정말 단순하지만, 대신에 Augmentation 방식, Loss, 배치 크기 등에 많은 신경을 쓴 것을 알 수 있습니다.
소개
기존 방식을 도입합니다. Generative 방법은 비용이 많이 들고 Representation Learning에 필요하지 않으며, Discriminative 방법은 Supervised Learning과 유사한 구조를 가지고 있지만 Unlabeled Dataset으로 학습한다(이 부분은 자세히 설명하지 않았지만 효율적인 방법은 다음과 같다. 않는다는 설명을 들었다).
Representation learning을 효과적으로 만들기 위해 논문은 다양한 요인을 실험했다.
1. 데이터 증대가 중요하다
2. 비선형 변환 도입
3. 대조적인 교차 엔트로피 손실 사용
4. 더 큰 배치 크기 사용
이 중 4가지가 있으며 논문에서는 기본적으로 ResNet-50을 사용하고 있으며, 그 외에 성능 평가는 이러한 요소에 중점을 두고 있다. 이러한 요소들을 활용하여 76.5%의 top-1 정확도와 SOTA를 달성했다고 합니다.
방법
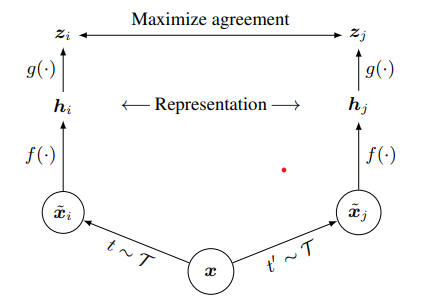
전체 네트워크의 구조는 다음과 같습니다.
t: 데이터 증대 방법
xi, xj: 증강 및 인쇄된 이미지
f: 특징 추출기(ResNet – 50)
g: 프로젝션 헤드

그리고 SimCLR의 의사 코드.
각 이미지(배치 크기)가 N개 있는 경우 각 이미지는 2개의 증가(N -> 2N)를 사용하여 증가되고, 네트워크를 사용하여 포함되고, 투영된 다음, 코사인 유사성을 사용하여 측정됩니다. 따라서 손실의 분자에는 다른 하나의 증강 영상과의 유사도만 계산하고, 분모에는 이를 제외한 2N-2개의 영상에 대한 비유사도를 계산한다. 학습 중인 네트워크는 특징 추출기와 프로젝션 헤드입니다. 이 과정을 보여주는 그림이 아래에 나와 있습니다.
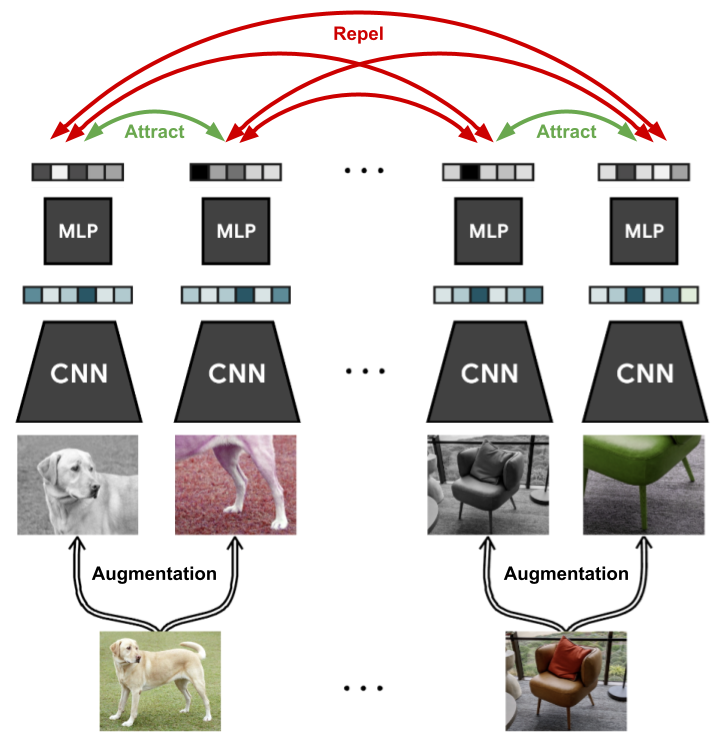
사용되는 확대 방법은 임의 자르기, 색상 왜곡 및 임의 가우시안 블러라고 합니다. 이와 관련하여
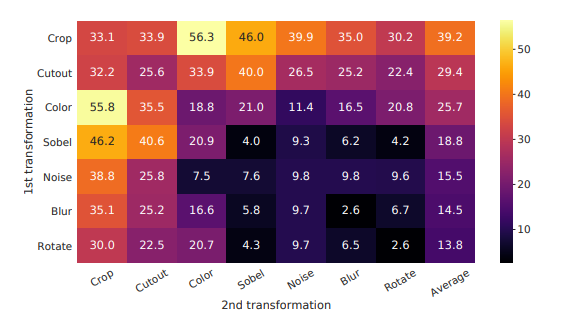
데이터 증대 방법에 대한 실험을 해보았으나 한 가지 증대만 사용하는 것은 큰 효과가 없었다고 한다. 그리고 기존의 많은 연구(ex. global-to local view 예측, 이웃 뷰 예측 등)는 목표를 달성하기 위해 많은 복잡성을 가지고 있지만 여기서는 random cropping(with resizing)이 그러한 목표를 달성하는 데 매우 효율적이라고 합니다. 포괄적인 목표. 하다. 여기서 말하고 싶은 것은 기존에 pretask에 대한 여러 가지 방법이 있지만 본 논문에서 사용한 방법(random cropping)을 사용하면 더 넓은 작업을 수행할 수 있다는 것이다.
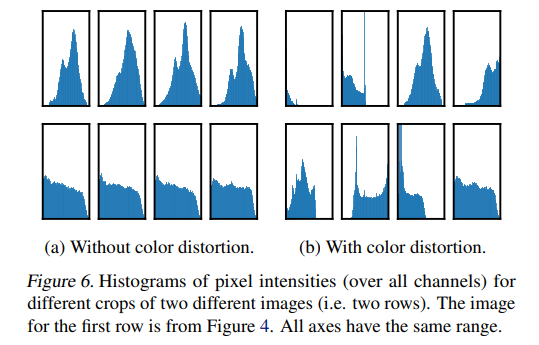
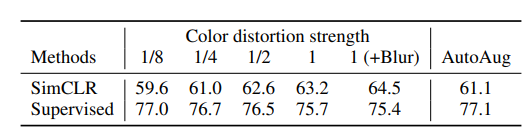
색상 왜곡을 적용했을 때와 적용하지 않았을 때의 픽셀 강도와 성능에 큰 차이가 있다고 하며, 적용해야 한다고 합니다.
저자가 사용한 손실은 NT-Xent 손실(표준화 온도 스케일 교차 엔트로피 손실)입니다.
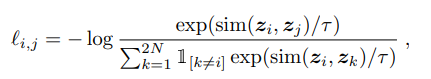
논문에서 우리는 또한 다양한 손실을 비교했습니다.


이것은 다른 손실과 그라디언트를 비교하는 표입니다.
1. l2 norm(cosine similarity)과 온도를 사용하는 것이 효과적이다.
2. 교차 엔트로피 이외의 다른 손실은 음성 샘플을 처리하지 않았다고 합니다.
저자도 배치 크기에 관심이 있었고, 에포크가 많을수록 배치 크기 성능이 크게 다르지 않았다고 합니다. 중요한 점은 배치 크기가 커질수록 성능이 높아지는데, 이는 수렴에 큰 도움이 된다고 합니다. 생각해보면 하나의 이미지가 하나의 배치 내에서 더 많은 네거티브 샘플과 다르다는 것을 학습하고 구별할 수 있기 때문에 성능이 향상될 것이라고 생각합니다.
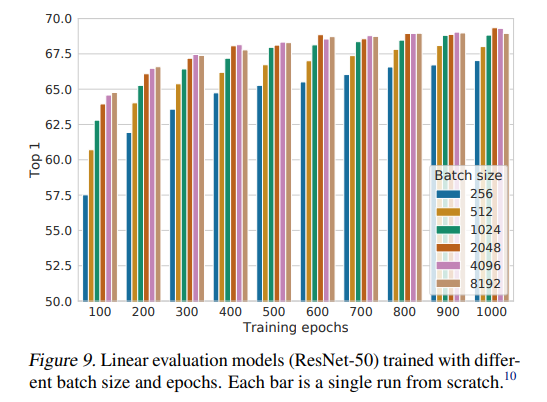
결론
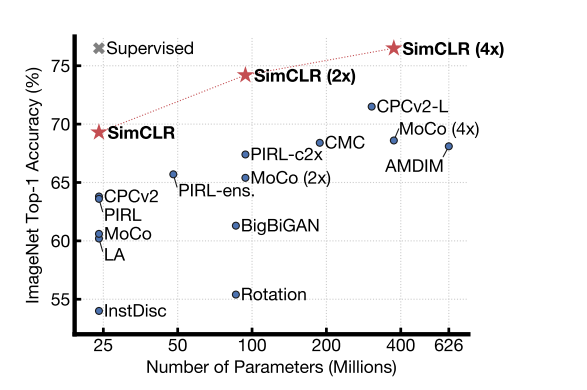
SimCLR의 성능입니다. 모델의 크기가 커질수록 지도 학습 모델과 비슷해짐을 알 수 있다.
https://arxiv.org/pdf/2002.05709.pdf
MoCo 논문을 읽고나서 어렵지 않았고, 다양한 하이퍼파라미터로 실험을 했기 때문에 흥미로운 논문이었습니다. 다음에 여기서부터 NT-xent loss에 대해 공부하려고 합니다. 틀린 부분은 지적해주시면 감사하겠습니다.